Robots.txt в 2026: синтаксис, AI-краулеры и проверка файла | SEOquick
Один файл robots.txt управляет тем, как Google и AI-краулеры обходят ваш сайт. Разбираем синтаксис, типичные ошибки и новые правила 2026 года.
Robots.txt — это текстовый файл в корне сайта, который управляет сканированием: он подсказывает поисковым и AI-краулерам, какие разделы обходить, а какие пропускать. Но запомните главное правило 2026 года: robots.txt управляет сканированием, а не индексацией. Чтобы убрать страницу из выдачи, нужен noindex, а не Disallow.
Каждый, кто занимается продвижением сайта, должен понимать смысл этого файла и уметь прописывать самые востребованные директивы. Правильно составленный robots.txt помогает экономить краулинговый бюджет и является базовым инструментом технического SEO. Ошибка же в одной строке способна закрыть от Google весь сайт или сломать рендеринг страниц.
Чтобы разобраться, как работает robots.txt, вспомним логику поисковых систем. Краулеры выполняют две задачи: обход интернета в поиске новой информации и индексирование контента, чтобы пользователи могли его находить. Переходя по миллиардам ссылок, бот ведёт себя как паук в паутине — обходит территорию и смотрит, что нового попало в сеть.
Прибыв на сайт, но перед сканированием, бот первым делом ищет файл robots.txt. Если файл есть — читает инструкции и действует в соответствии с ними. Если файла нет или в нём нет запретов — бот продолжает обходить всё подряд.

Что есть у конкурента, а у тебя – еще нет? Правильно – трафик. SEOquick в помощь!
Привлечем тебе на сайт массу трафика через SEO.
Сделаем это исключительно белыми методами, без фильтров и санкций от Google.
Проведем глубокую оптимизацию: усилим контент, нарастим ссылки и репутацию. И всё получиться!
Первое знакомство с Robots.txt
Robots.txt — это обычный текстовый файл, созданный веб-мастером для инструктирования краулеров. В нём прописаны рекомендации о том, как сканировать страницы сайта. Говоря простым языком: в файле указано, куда роботу заходить не надо, что обходить для поиска, а что — нет.
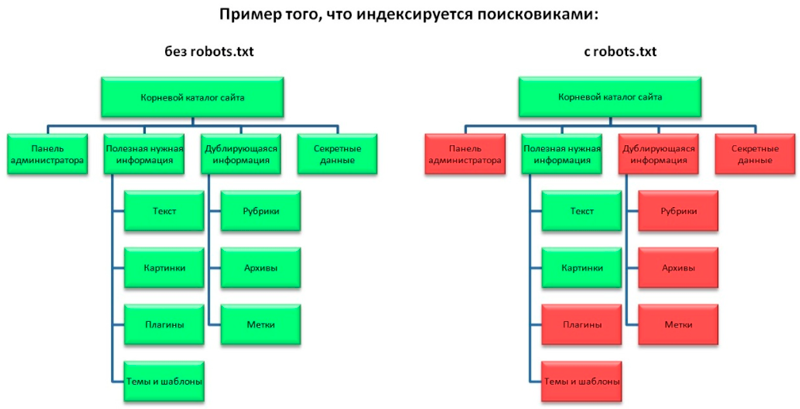
Файл создают в корневом каталоге сайта. Всякий раз, приходя на ресурс, краулер ищет его в одном конкретном месте — основном каталоге домена. Если по адресу example.com/robots.txt файла нет, бот считает, что инструкций нет вообще, и сканирует всё.
Важные технические нюансы 2026 года:
- Файл чувствителен к регистру в имени: он должен называться именно «robots.txt» (не Robots.txt и не robots.TXT).
- Это общедоступный файл — его видит любой пользователь по адресу /robots.txt. Поэтому никогда не используйте его, чтобы спрятать конфиденциальные данные.
- На каждом поддомене должен быть свой robots.txt: и blog.example.com, и example.com обходятся по отдельным файлам.
- Кодировка — стандартная UTF-8, иначе краулеры могут прочитать содержимое некорректно.
- Лимит размера для Google — 500 КБ; всё, что больше, игнорируется.
Памятка: если robots.txt лежит не в корне (например, example.com/index/robots.txt), он не будет принят во внимание.
Зачем всё это нужно? Прежде всего для экономии краулингового бюджета и порядка в индексе: чтобы краулер не тратил время на служебные разделы, фильтры и параметры, а сосредоточился на важных страницах. Грамотный robots.txt — обязательная часть технического аудита сайта.
Ответы на частые вопросы по ссылкам можно получить из нашего видео:
Что можно и чего нельзя делать через robots.txt
Robots.txt контролирует доступ краулеров к определённым областям сайта. Это полезно, но опасно: одной строкой можно случайно запретить Googlebot обходить весь ресурс. Чтобы не запутаться, держите в голове чёткую таблицу задач.
Где robots.txt уместен:
- Экономия краулингового бюджета. Закрыть от обхода фильтры, параметры сортировки (?sort=, ?color=), результаты внутреннего поиска, бесконечные комбинации URL.
- Служебные разделы. Админка, корзина, личный кабинет, технические папки.
- Указание Sitemap. В файле полезно прописать путь к XML-карте сайта.
- Снижение нагрузки на сервер от слишком частых обращений краулеров к тяжёлым разделам.
Где robots.txt бесполезен или вреден:
- Удаление страницы из индекса. Disallow не удаляет URL из выдачи — нужен noindex или инструмент удаления URL в Search Console.
- Сокрытие приватных данных. Используйте авторизацию и пароль, а не robots.txt.
- Блокировка CSS и JS. Если закрыть ресурсы, нужные для рендеринга, Google увидит «сломанную» страницу. По данным аудита 2026 года, около 63% крупных сайтов случайно блокируют важные CSS/JS из-за неаккуратных wildcard-правил.
Обратите внимание: страница, закрытая в robots.txt, всё равно может появиться в результатах поиска, если на неё установлена ссылка на этом сайте или вне его — только без описания (сниппета).
Чтобы проверить наличие файла, введите в адресную строку корневой домен и добавьте /robots.txt. Например, файл Moz лежит по адресу moz.com/robots.txt.

Синтаксис Robots.txt: основные директивы
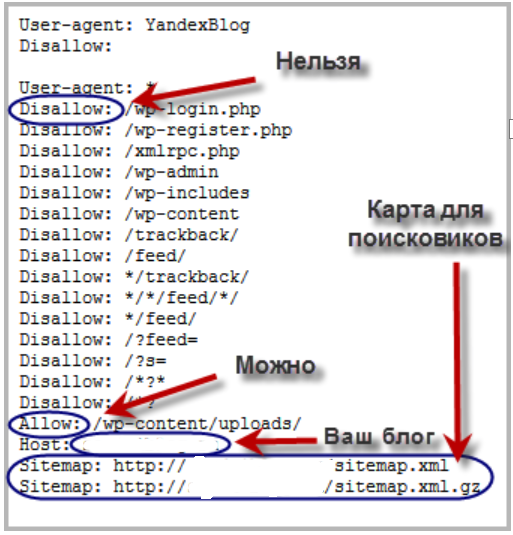
Синтаксис robots.txt прост. Каждая строка — это поле, двоеточие и значение. Имена полей не зависят от регистра, а вот значения путей (после Disallow/Allow) регистрозависимы. В самой простой форме файл выглядит так:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: https://example.com/sitemap.xml
Разберём ключевые директивы, актуальные в 2026 году:
- User-agent — имя краулера, которому адресованы правила. Звёздочка (*) означает «для всех ботов». Блоки правил для разных User-agent разделяются пустой строкой.
- Disallow — запрет на обход указанного пути. Для каждого пути одна строка Disallow.
- Allow — разрешение на обход страницы или подпапки, даже если родительская папка закрыта. Поддерживается Google и Bing.
- Sitemap — указание на расположение XML-карты. Должен быть полный URL с протоколом. Можно указать несколько карт.

Если файл содержит правила для нескольких User-agent, краулер применяет тот блок, который адресован конкретно ему. Все остальные боты следуют общим директивам в группе User-agent: *.
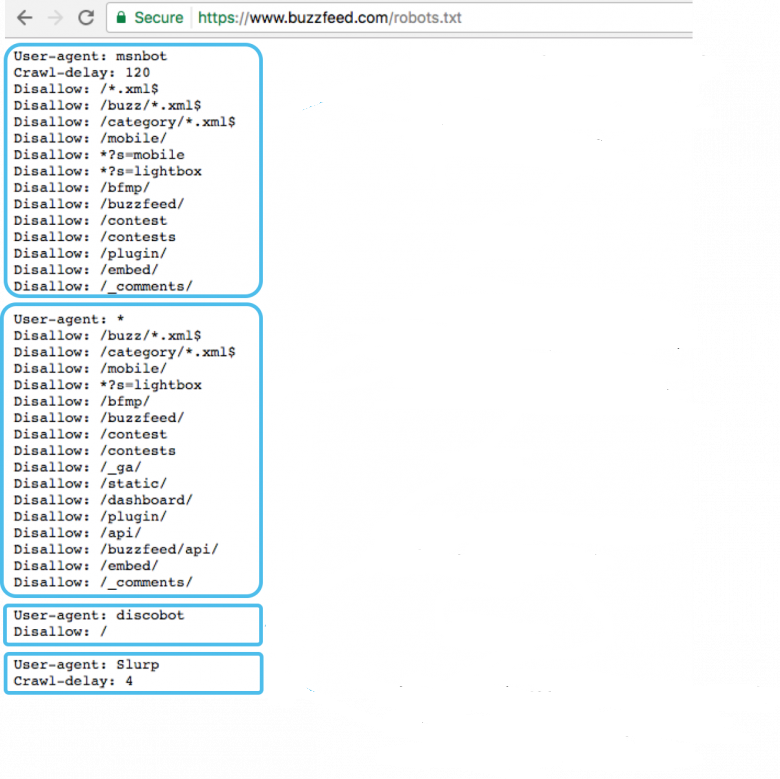
Важный нюанс: директива Crawl-delay (задержка сканирования) Googlebot-ом не поддерживается. Управлять скоростью обхода для Google нужно через настройки в Search Console, а не через robots.txt.
В работе со страницами и подпапками помогают спецсимволы (регулярные выражения):
- * — подстановочный символ, заменяет любую последовательность символов;
- $ — соответствует концу URL-адреса;
- # — комментарий, всё после него краулер игнорирует.
Несколько практических примеров. Закрыть весь сайт от всех краулеров (актуально для сайта на стадии разработки):
User-agent: * Disallow: /
Открыть весь сайт для обхода — пустой Disallow означает «можно всё»:
User-agent: * Disallow:
Закрыть конкретную папку только для Googlebot:
User-agent: Googlebot Disallow: /example-subfolder/
Закрыть отдельную страницу только для Bingbot:
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
AI-краулеры в robots.txt: главная новая глава 2026 года
Самое важное изменение последних лет — это AI-краулеры. Сегодня robots.txt управляет не только Google, но и ботами больших языковых моделей. Здесь критично понимать разницу между двумя типами AI-ботов:
- Training-краулеры собирают контент для обучения моделей: GPTBot (OpenAI), Google-Extended (Gemini), ClaudeBot (Anthropic), CCBot (Common Crawl). Блокировка этих ботов не даёт использовать ваш контент для тренировки.
- Search / RAG-краулеры обращаются к сайту в момент запроса пользователя и дают цитирование со ссылкой: OAI-SearchBot и ChatGPT-User (OpenAI), PerplexityBot, Claude-SearchBot. Блокировка этих ботов лишает вас показов и трафика из AI-поиска.
Рекомендуемая стратегия для большинства бизнесов в 2026: блокировать training-краулеры, но разрешать search-краулеры. Так ваш контент попадает в ответы AI-поисковиков с атрибуцией и приносит переходы, но не используется для обучения чужих моделей. Пример такого блока:
# Блокируем обучение моделей User-agent: GPTBot Disallow: /User-agent: Google-Extended Disallow: /
User-agent: ClaudeBot Disallow: /
User-agent: CCBot Disallow: /
Разрешаем AI-поиск с цитированием
User-agent: OAI-SearchBot Allow: /
User-agent: PerplexityBot Allow: /
Важные предостережения. Старые токены Claude-Web и anthropic-ai больше не активны — сайты, блокирующие только их, на самом деле не блокируют актуального ClaudeBot. И помните: агрессивные парсеры (например, Bytespider или «скрытые» краулеры) могут игнорировать robots.txt и подделывать User-Agent. Реально защитить краулинговый бюджет от таких ботов можно только на уровне сервера или WAF. Если вы внедряете AI-инструменты в продвижение, имеет смысл заранее продумать политику доступа — мы помогаем с этим в рамках разработки AI-инструментов.
Robots.txt против noindex: ключевое различие
Это самая частая и самая дорогая ошибка. Запомните формулу: robots.txt управляет сканированием, noindex управляет индексацией.
- Disallow в robots.txt запрещает краулеру заходить на страницу. Но если на страницу ведут внешние ссылки, она всё равно может попасть в выдачу — без сниппета.
- noindex (мета-тег
<meta name="robots" content="noindex">или HTTP-заголовок X-Robots-Tag) запрещает добавлять страницу в индекс.
Главная ловушка: нельзя одновременно ставить Disallow и noindex на одну страницу. Если вы закроете URL в robots.txt, краулер не сможет зайти на страницу и не увидит мета-тег noindex — а значит, страница останется в индексе. Правильно так: чтобы убрать страницу из выдачи, разрешите её обход и добавьте noindex. Чтобы сэкономить краулинговый бюджет на разделе, который и так не должен сканироваться, используйте Disallow.
Проверка robots.txt и типичные ошибки
Неправильно работающий robots.txt — это проблема, на выявление которой уходит время. Прежде чем выложить файл, проверьте его. Google предоставляет отчёт robots.txt прямо в Search Console (Настройки → отчёт robots.txt): он показывает дату последней загрузки, ошибки и предупреждения.
Самые частые ошибки, которые мы встречаем при поисковом продвижении сайтов:
- закрывают весь сайт строкой
Disallow: /и забывают убрать после переноса со staging; - блокируют CSS и JS, из-за чего Google видит сломанную, «не-мобильную» страницу;
- закрывают URL в robots.txt и ждут, что страница исчезнет из индекса (а нужен noindex);
- забывают указать Sitemap;
- не перепроверяют robots.txt после редизайна или миграции;
- блокируют только устаревшие AI-токены, оставляя актуальных ботов без правил.
Если страница после запрета всё равно висит в выдаче, проверьте в Search Console, переиндексировал ли Google сайт, и нет ли внешних ссылок на закрытую страницу. Своевременный анализ помогает избежать неприятностей и экономит время. Все правила лучше сверять с официальной документацией: введение в robots.txt от Google и как Google интерпретирует robots.txt.
FAQ: частые вопросы про robots.txt
Удалит ли Disallow страницу из поиска Google?
Нет. Disallow запрещает только сканирование. Если на страницу есть внешние ссылки, она может остаться в выдаче без описания. Для удаления используйте noindex или инструмент удаления URL в Search Console.
Можно ли ставить noindex прямо в robots.txt?
Нет. Google официально не поддерживает директиву noindex в robots.txt с 2019 года. Используйте мета-тег robots или HTTP-заголовок X-Robots-Tag на самой странице, не закрывая её при этом в robots.txt.
Нужно ли блокировать AI-краулеры?
Зависит от стратегии. Если не хотите, чтобы ваш контент использовали для обучения моделей, блокируйте GPTBot, Google-Extended, ClaudeBot, CCBot. Но разрешайте search-краулеры (OAI-SearchBot, PerplexityBot), чтобы оставаться в AI-поиске и получать переходы.
Почему нельзя блокировать CSS и JS?
Без этих файлов Googlebot не может корректно отрендерить страницу и видит её «сломанной» — это бьёт по мобильной оценке и ранжированию. Всегда оставляйте открытыми ресурсы, нужные для рендеринга.
Поддерживает ли Googlebot директиву Crawl-delay?
Нет. Googlebot игнорирует Crawl-delay. Управлять скоростью обхода для Google нужно через настройки в Search Console.
Нужен ли robots.txt каждому поддомену отдельно?
Да. Каждый поддомен обходится по своему файлу. У blog.example.com и example.com должны быть отдельные robots.txt в корне.
Performance Max для интернет-магазина: кейс настройки и оптимизации
Как настроить Performance Max для интернет-магазина: кейс с ростом ROAS с 2,8 до 5,1, фид Merchant Center, asset-группы, бюджет и оптимизация.
Читать →Ключевые слова Google Ads в 2026: подбор, типы соответствия, минус-слова
Как работают ключевые слова Google Ads в 2026: реальное поведение типов соответствия, подбор семантики, структура кампаний, минус-слова и PMax.
Читать →Кейс BeCoin.net: как SEOquick разработал мультиязычную платформу прогнозов для трейдеров
Как SEOquick разработал BeCoin.net: UX, живые рыночные таблицы, страницы прогнозов, мультиязычная SEO-структура, аналитика, GSC-контроль и безопасный blue/green deployment.
Читать →Хотите применить это к своему сайту?
Разберем текущую ситуацию, найдем первые точки роста и предложим формат работы без лишней теории.