AI в SEO задачах в 2026: Как стать менеджером нейросетей, а не их оператором
Как стать менеджером нейросетей, а не оператором. Статистика ошибок моделей 2025 года, стек инструментов и пошаговая методология повышения продуктивности.
В этой статье мы разберем анатомию современного AI-воркфлоу: почему новые модели врут чаще старых, как заставить их работать на бизнес-задачи и почему «параллельный запуск» — это единственный способ выжить в 2026 году.
Первоочередной задачей сегодня у нас стоит – именно автоматизация. Мы хотим, чтобы те вещи, за которые клиенту приходилось переплачивать, не нужно было больше это делать. К примеру, качественные статьи. Журналистсткие пресс релизы. Но благодаря ИИ сегодня мы знаем, что например сайт msn.com просто состоит из сгенерированных статей. А при поиске ответов в ИИ вы видите ссылки – и 50% из них уже сгенерированы в ИИ.
И конечно, каждый владелец бизнеса хочет сделать так, чтобы 10,000 страниц категорий товаров или 20,000 товаров получили шикарные описания, странички услуг под ключевые слова были оптимизированы за день. Но почему до сих пор есть барьеры, и многие о них может и догадываются, но еще не сталкивались. Кто сталкивался, с вас жирный лайк.
Часть 1. Какие проблемы с AI сегодня

Эйфория от первых дней ChatGPT прошла. На смену ей пришел прагматизм и, честно говоря, легкое раздражение. Если вы используете нейросети для реальной работы, а не для генерации картинок с котиками, вы наверняка столкнулись с «детскими болезнями» даже самых продвинутых моделей. Я по своему опыту уже столкнулся с тем, что запускаю параллельно несколько нейронок. Одна из них собирает отчет, другая анализирует документ, третья – генерирует приложение, которое я буду использовать в дальнейшем.
Недавно просто скопировал историю перепалки в чате, закинул в нейронку, и попросил найти решение, и о – чудо – оно нашлось.
1. Кризис галлюцинаций в новых моделях
Главная опасность ИИ — он никогда не сомневается. Он может с абсолютной уверенностью привести выдуманную цитату закона или несуществующую техническую характеристику. Специалист не может «пробежать глазами» текст, ему нужно проверять каждое существительное и цифру. Парадокс 2025 года: чем умнее модель, тем изощреннее она врет. Казалось бы, новые reasoning-модели (рассуждающие) должны быть точнее. Но статистика и практика говорят об обратном.
Рост галлюцинаций у новых моделей
Данные: Бенчмарки 2025 года
- Цифры не лгут (в отличие от ИИ): Согласно официальному System Card от OpenAI, рассуждающие модели o3 и o4-mini в свое время показали уровень галлюцинаций в 33% и 48% соответственно на бенчмарке PersonQA — против 16% у более ранней o1. (Источник: TechCrunch, OpenAI System Card Report). И хотя флагманы 2026 года (GPT-5.5, Claude Opus 4.5, Gemini 3.1 Pro) научились заметно реже выдумывать факты, проблема не исчезла: чем длиннее и «увереннее» рассуждение, тем выше риск получить правдоподобную, но ложную деталь.
- Почему это происходит? Исследователи отмечают, что модели, обученные на цепочках рассуждений (Chain of Thought), склонны к “over-reasoning”. Вместо того чтобы просто сказать «я не знаю» или выдать факт, модель начинает выдумывать правдоподобное обоснование, пытаясь “угодить” логике запроса.
- Зона риска: Юриспруденция и точные науки. Мир уже видел кейсы (например, дело Mata v. Avianca в США), когда юристы приносили в суд выдуманные прецеденты. Если вы просите модель найти статистику для отчета клиенту — проверяйте каждое число. ИИ может идеально посчитать конверсию, но выдумать сам факт существования исследования.
Нейросети могут генерировать логически связный, но фактически неверный контент, что критично в таких темах, как медицина или юриспруденция. Приходится или перепроверять или вообще перегенерировать все с нуля.
2. «Водяное» проклятие
Западные эксперты по AI-этике называют это феноменом “Sycophancy” (Сикофанство или Угодничество). Исследование, опубликованное на портале Anthropic, подтверждает: модели, прошедшие обучение с подкреплением (RLHF), склонны соглашаться с предубеждениями пользователя, даже если они неверны, чтобы получить “одобрение”. Это выливается в бесконечные вежливые вступления («В современном мире цифрового маркетинга…») и подтверждение ваших же ошибок. В тестах на честность модели чаще выбирали “лестный”, но неверный ответ, чем сухой факт, если чувствовали, что пользователь этого ожидает.
Из недавних примеров – долго сидел и изучал ТЗ для работы, где нужно было сделать реально две вещи – аналитику и кампанию в PMax на товары, но ТЗ было просто на 10 страниц. Вы просите краткий анализ, а получаете эссе в стиле школьника, которому нужно набрать объем слов.
- Проблема: Модели обучены быть вежливыми и предупредительными. Это выливается в бесконечные вступления («В современном мире цифрового маркетинга важность PMax кампаний трудно переоценить…») и заключения.
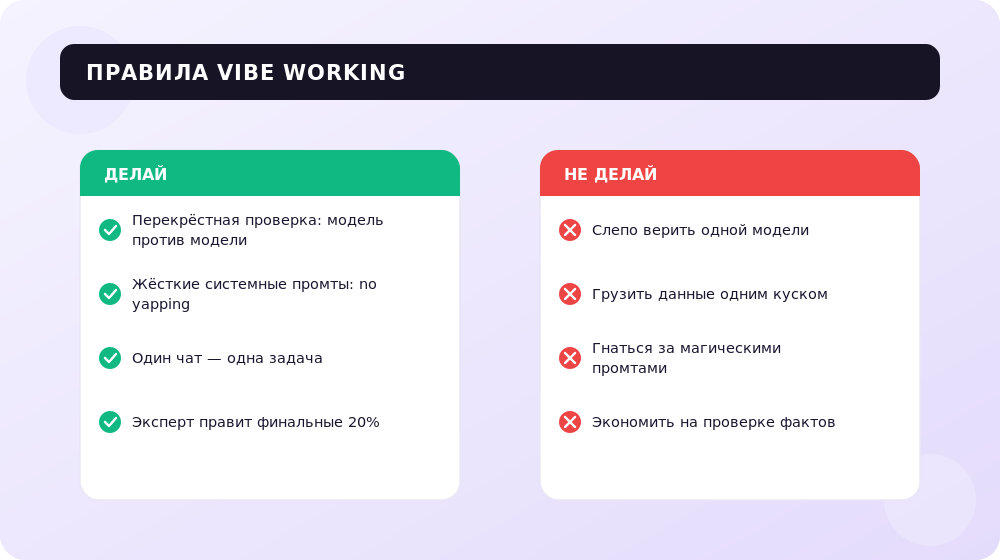
- Решение: Жесткие системные промты. Фразы «no yapping» (без болтовни), «only raw data» (только сырые данные) или «ответ начни сразу с пункта 1» становятся обязательными атрибутами vibe-working.
Без ручной правки ИИ-тексты быстро становятся узнаваемыми из-за характерных вводных слов и структур. Поисковики в 2026 году легко идентифицируют такие паттерны, снижая охваты «ленивым» ресурсам. И контент может содержать фейки или ничего ценного, кроме того, что и так известно. Все потому, что ИИ не обладает личным опытом (Experience) и не может предоставить авторские кейсы или экспертные мнения, которые Google в 2026 году ценит выше, чем когда-либо.
3. Амнезия контекста и Excel-слепота
Несмотря на заявленные контекстные окна в миллионы токенов, модели страдают избирательной памятью. Я поэтому ВСЕГДА начинаю новый чат. Не забывайте, при создании материала он обычно берет топ-10 статей из поиска и перефразирует их, выдавая за уникальный контент – так что проверять нужно через Copyleaks или наш инструмент Unmiss AI Content Detector.
Потеря контекста при длинном диалоге
- Потеря данных: Исследователи из Стэнфорда (вместе с UC Berkeley) опубликовали ставшую знаменитой работу о феномене “Lost in the Middle” (Потерянные в середине). Точность извлечения информации высока в начале промпта и в самом конце. Но данные, находящиеся в середине длинного контекста (например, 50-я строка в Excel-файле из 100), модель игнорирует или галлюцинирует.
- Эффект золотой рыбки: К концу длинного диалога модель может забыть инструкции, данные в начале.
- Лайфхак: Никогда не «скармливайте» модели огромные массивы данных одним куском без предварительной структуры. Используйте RAG-системы (как NotebookLM) или разбивайте задачу на части.
И проверяйте. Системы ограничены базой, на которой они учились, и могут выдавать предвзятые или устаревшие рекомендации. Автоматизация не означает «нажал и забыл»; на проверку и редактуру (fact-checking) ИИ-контента часто уходит столько же времени, сколько на написание текста с нуля.
4. Тональная глухота
ИИ пока плохо чувствует «вайб» бренда. Он часто скатывается в то, что дизайн-критики называют “Corporate Memphis” в тексте — безликий, приторно-позитивный стиль, характерный для LinkedIn.
- Наблюдение: Эксперты по контент-маркетингу отмечают, что AI-тексты часто перенасыщены словами-маркерами вроде “unleash”, “landscape”, “game-changer”, “delve” (последнее стало мемом как признак AI-текста). К 2026 году эти клише не вывели даже GPT-5.5 и Gemini 3.1 — паттерн «зашит» в обучающих данных.
- Решение: Использование Perplexity (с Deep Research) для поиска фактов и Claude (Opus 4.5 / Sonnet 4.6) для стилизации — он по-прежнему лучше других имитирует человеческие нюансы речи, но с жестким запретом на клише.
Часть 2. Светлая сторона: Что ИИ делает лучше людей (уже сейчас)
Несмотря на минусы, есть задачи, где нейросети дают фору команде джуниоров. Секрет успеха — в использовании специализированных инструментов, а не одного лишь ChatGPT.
1. Аналитика конкурентов (Связка SERanking + Gemini)
Это настоящий game-changer для маркетологов. Вместо ручного перебора сайтов:
- Делаем выгрузку из SERanking или SERPSTAT (ключи, трафик, позиции).
- Загружаем CSV в Gemini 3.1 Pro (на 2026 год он лидирует по анализу данных и рассуждениям, плюс огромное окно контекста).
- Используем Deep Research (в Gemini, Perplexity или ChatGPT) для качественного анализа, а Grok 4 — как дешевую «вторую пару глаз» для перекрестной проверки выводов.
- Результат: Структурированная таблица, где подсвечены не просто отличия, а «белые пятна» в стратегии конкурентов, куда можно ударить своим бюджетом.
Как это работает у нас: в SEOquick такая связка стала рутиной при аудитах конкурентов и сборе семантики. Нейросеть разбирает выгрузку и предлагает гипотезы по структуре и контент-гэпам, а SEO-специалист отбирает реалистичные точки роста под бюджет клиента. Дальше эти гипотезы превращаются в готовые промты — мы собрали целую подборку из 50 мега-промптов для ChatGPT и Gemini под SEO.
2. Ревью кода (Claude — король разработки)
Пока GPT-5.5 удерживает паритет в общих задачах, Claude (линейка Opus 4.5 и Sonnet 4.6) остается де-факто стандартом для программистов: на бенчмарке SWE-bench Verified свежие версии берут планку под 87% — лучший результат среди коммерческих моделей на 2026 год. Разработчики ценят Claude за “меньшее количество ленивого кода” и аккуратный рефакторинг.
- Он не просто находит ошибку, он объясняет почему этот кусок HTML/CSS сломает верстку в Safari.
- Vibe coding в действии: вы копируете «лапшу» из кода, кидаете в Claude и просите «сделать красиво и безопасно». В 9 из 10 случаев результат можно деплоить в продакшн.
Кейс SEOquick: мы пользуемся этим ежедневно. Часть внутренних SEO-инструментов на сайте (детектор AI-контента, кластеризатор ключей, генератор микроразметки) собрана именно так — ТЗ + итеративная отладка кода через Claude, где живой специалист выступает ревьюером, а не оператором. То, что раньше занимало у разработчика неделю, теперь укладывается в пару вечеров.
3. Генерация ТЗ из хаоса (NotebookLM)
Это, пожалуй, самое недооцененное применение.
- Сценарий: У вас есть заметки в телефоне, пара голосовых сообщений от клиента, PDF с брендбуком и переписка в Telegram.
- Решение: Загружаем всё это «добро» в NotebookLM от Google. Это RAG (Retrieval-Augmented Generation) система, которая работает только по вашим документам.
- Промт: «На основе этих источников составь строгое техническое задание для разработчика на создание лендинга».
- Итог: Идеально структурированный документ без галлюцинаций (потому что источник ограничен вашими файлами).
Специализация моделей (Сильные стороны)
4. SEO-магия (Unmiss.com и микроразметка)
Ручное прописывание метатегов в 2026 году — это моветон. Западные SEO-эксперты (например, с Search Engine Journal) говорят о переходе от ключевых слов к Semantic SEO (Смысловому SEO).
- Специализированные инструменты (например, модуль AI в Unmiss.com) анализируют не просто ключевые слова, а смысл контента. Они генерируют Title и Description, которые нравятся и Google, и людям (CTR растет).
- Schema.org: Просить нейросеть написать JSON-LD разметку для страницы — это самый быстрый способ получить расширенные сниппеты в выдаче. Главное — дать ей код страницы (или воспользоваться парсером).
- GEO вместо классического SEO: в 2026 году половина пользователей получает ответы прямо в ChatGPT Search, Perplexity и Google AI Overviews — без перехода на сайт. Поэтому мы оптимизируем страницы не только под Google, но и под цитируемость в ответах нейросетей: четкие определения, FAQ, экспертные цифры. Подробно разобрали это в гайдах по GEO-оптимизации сайта под GPT и по SEO в эпоху ChatGPT.
5. Объяснение сложного простым языком
Идеальный кейс «переводчика с технического на клиентский».
- Ситуация: Программист написал документацию к API, которую не понимает даже Project Manager.
- Действие: Используйте промт, основанный на “Feynman Technique” (Техника Фейнмана): “Объясни этот концепт так, как будто ты объясняешь его 12-летнему ребенку, используя аналогии из реального мира”.
- Результат: Клиент доволен, потому что наконец-то понял, за что платит деньги.
Часть 3. Vibe Working: Методология новой продуктивности
Как собрать это все в единую систему? Откажитесь от идеи «одного окна». Ваше рабочее место теперь выглядит как пульт управления полетами.
Стек «Менеджера нейросетей»
| Задача | Инструмент (Рекомендация) | Почему? |
|---|---|---|
| Кодинг / Верстка | Claude Opus 4.5 / Sonnet 4.6 | Лучшее понимание контекста кода и меньше багов (топ SWE-bench на 2026). |
| Работа с большими данными / Google Таблицы | Gemini 3.1 Pro | Глубокая интеграция с экосистемой Google, лидер по анализу данных, огромное окно контекста. |
| Поиск и фактчекинг | Perplexity (Comet, Deep Research) / Gemini Deep Research | Доступ к реальному времени, ссылки на источники. |
| Быстрая перепроверка / агентные задачи | Grok 4 | Самый дешевый из флагманов, сильный в tool-use — удобен как «вторая пара глаз». |
| Структурирование знаний / ТЗ | NotebookLM | Работает строго по загруженным источникам, ноль отсебятины. |
| SEO и Метатеги | Unmiss.com / Specialized Tools | Анализ контента + знание алгоритмов ранжирования. |
| Тексты / E-mail / Рерайт | ChatGPT (GPT-5.5) | Сильнейший в креативном письме и стилистической гибкости (при правильной настройке). |
Золотые правила Vibe Working
- Принцип перекрестного допроса: Никогда не верьте одной модели в важных вопросах. Если GPT-5.5 выдала статистику — попросите Perplexity найти источник. Если Gemini написал код — попросите Claude проверить его на баги.
- Промт-инженерия мертва, да здравствует контекст: Перестаньте искать «волшебные промты». Вместо этого учитесь собирать качественный контекст. Лучший промт — это четкое ТЗ и примеры (Few-Shot Prompting).
- Правило 80/20: Нейросеть делает 80% рутины. Оставшиеся 20% времени вы тратите не на создание с нуля, а на экспертную оценку и «докручивание». Это и есть vibe-working.
- Уникальность через синтез: Чтобы не плодить контент-клон, используйте нейросети для синтеза идей. Попросите дать 20 заголовков, выберите 3 лучших, смешайте их и допишите сами.
- Самообучайтесь. Длительная работа только с ИИ притупляет навыки самого специалиста. Возникает эффект «слепого доверия», когда редактор перестает замечать ошибки из-за усталости от огромных объемов генерации.
- Не экономьте. На втором этапе – проверки фактов – приходится нанимать вторую (более дорогую и мощную) нейросеть для проверки работы первой. Это сильно удорожает инфраструктуру и требует сложной настройки метрик оценки качества. Ну и в итоге – качественные модели (уровня GPT-5.5 или Claude Opus 4.5) стоят дорого при массовой генерации. Попытка сэкономить и использовать дешевые открытые модели (Llama, локальные сборки и т.д.) часто приводит к резкому падению качества, что требует еще больше времени на ручную проверку.
Заключение
Мне часто говорят, вас ИИ заменит. И да, и нет. ИИ заменит тех, кто не выкупает, как им пользоваться. Но не заменит тех, кто понял.
Сегодня автоматизация — это не «замена человека», а изменение его роли. Основная сложность сместилась из области «написать текст» в область «настроить пайплайн, обеспечить подачу чистых данных и организовать многоуровневый контроль качества». Тот, кто не справляется с технической стороной проверки, получает сайт, забитый «галлюцинациями», который быстро попадает под фильтры поисковых систем.
Мы стоим на пороге интересного времени. ИИ не заменил нас, но он навсегда изменил то, как мы работаем. Vibe Working — это отказ от перфекционизма в пользу скорости и итеративности.
Да, нейросети галлюцинируют. Да, они льют воду. Но тот, кто научился фильтровать этот поток и использовать сильные стороны каждой конкретной модели, получает суперспособность: делать работу целого отдела в одиночку за один вечер.
Главное — не забывать: вы здесь босс. А они — всего лишь очень умные, но иногда пьяные стажеры.
Performance Max для интернет-магазина: кейс настройки и оптимизации
Как настроить Performance Max для интернет-магазина: кейс с ростом ROAS с 2,8 до 5,1, фид Merchant Center, asset-группы, бюджет и оптимизация.
Читать →Ключевые слова Google Ads в 2026: подбор, типы соответствия, минус-слова
Как работают ключевые слова Google Ads в 2026: реальное поведение типов соответствия, подбор семантики, структура кампаний, минус-слова и PMax.
Читать →Кейс BeCoin.net: как SEOquick разработал мультиязычную платформу прогнозов для трейдеров
Как SEOquick разработал BeCoin.net: UX, живые рыночные таблицы, страницы прогнозов, мультиязычная SEO-структура, аналитика, GSC-контроль и безопасный blue/green deployment.
Читать →Хотите применить это к своему сайту?
Разберем текущую ситуацию, найдем первые точки роста и предложим формат работы без лишней теории.